1.执行一条select语句期间执行了什么
建立连接
查询缓存:8.0以删除此模块
在当前语句执行之前会解析出当前语句的第一个字段,如果是select 的则会查询缓存,sql语句查询出的结果是以键值对存储在缓存中的,如果命中则直接返回,不会向下执行。但是对于经常更新的表来说,缓存功能就很鸡肋,因为每一次发生表更新,当前表内的的所有缓存都会更新
解析SQL
执行SQL
预处理阶段:检查表或者字段是否存在
优化阶段:基于查询成本的考虑,选择查询成本最小的执行计划
执行阶段:根据计划执行SQL查询语句
2.MySQL一行记录时怎么存储的
myslq的null值是怎么存放的?
mysql对的compact行格式中 会用null值列表来标记null的列
null值列表会占用1字节空间。
mysql如何知道varchar(n) 实际占用数据的大小?
mysql的compact航哥时钟会用 变长字段长度列表 存储变长字段实际占用的数据大小
varchar(n) 最大取值是多少?
一行记录最大取值为 65535字节,需要减去变长字节列表(2字节)和 null值列表(1字节)
如果一张表只有一个 varchar(n) 字段,且允许为 NULL,字符集为 ascii。varchar(n) 中 n 最大取值为 65532。
行溢出后,mysql是怎么处理的
如果一个数据页存放不了一条记录,innodb存储引擎会自动将溢出的数据存放到溢出页中。
当发生行溢出时,记录的真实数据只会保存改页的一部分数据,会把剩余的数据放进溢出页中,在真实数据中会使用20字节存储指向溢出页的地址。
3.索引分类
按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
按「字段个数」分类:单列索引、联合索引。
4.为什么Mysql innodb 选择b+tree作为数据索引的数据结构?
b+ tree vs b tree
在存储相同的数据的情况下,b tree 会比 b+tree要高,磁盘io次数更多
b+tree 的叶子节点 使用了双向链表,可以支持范围查询,b tree做不到这一点。
b+ tree vs 二叉树
二叉树高度不固定,b+ tree在千万级别的数据量下,高度依然在3~4层,也就说只需要3~4次io就能差到数据
b+ tree vs hash
hash查询快 但是不支持范围查询
5.什么时候适用索引
字段具有唯一性的时候
经常用where 查询条件的字段
经常用语group by 和 order by 的字段
6.什么时候不需要创建索引
where group order 用不到的条件
大量数据不唯一的字段
经常修改的字段
7.什么时候索引会失效
使用模糊查询 like 关键字 通配符在左侧
使用or关键字左侧为索引字段, 右侧字段非索引字段
对索引列 做了 计算、函数、类型转换
8.有什么优化索引的方法
前缀索引优化
覆盖索引优化
主键索引最好是自增
防止索引失效
9.从数据页的角度看 b+ 树
innodb 是按数据页为单位 读写的,默认数据页大小为 16kb,每个页通过双向链表联系,在物理上不连续,在逻辑上连续
如果叶子节点存储的是具体的数据,说明它是聚簇索引。如果存储的是主键值,说明它是二级索引
在使用二级索引查询数据,如果查询的数据能在二级索引中找到,就叫做覆盖索引。如果没找到,拿到主键值又,又去聚簇索引中查询,这个就叫做回表。
10.tree 作为 索引的区别
二叉树:不能高度自适应,如果插入的每个都是树中的最大节点,那么二叉树会退化成链表,此时查询的复杂度会从O(logN)转变成O(N),而且每个节点最多只能插入两个子节点,树的高度会越来越高,io的次数会越来越多
b tree:虽然b tree 的高度能够自适应,不会退化成链表,但是它的每个主节点只能有两个子节点,高度也会越来越高,其次就是因为其中每个节点中都是存放了实际的数据,而且是连续的,在插入或是删除 会使 b tree 的结构变化很大。其次就是在范围查询中b tree 只能通过遍历来完成范围查询,这个会涉及到较多次数的io,性能低于b+ tree
b tree 它的每个节点都存有值,不能判断具体要走哪个分支,需要多次递归才能找到需要的数据
b+ tree :高度自适应,非叶子节点只存放索引,叶子节点才会存放具体的数据。一个节点可有多个子节点,使得b+ tree 矮而宽,大大减少了io次数。叶子节点之间用双向链表连接,有利于范围查询。
11.索引失效的场景
隐式转换 ,在mysql中 拿字符串和数字进行比较,会自动的将字符串转化成数字。如果此时字符串列是索引,那么索引会发生隐式转换,从而索引失效,因为隐式转换是使用 cast函数实现的
函数内 或 做计算,因为索引保存的是索引字段的原始值
联合索引 不符合 最左原则
因为联合索引是按照最左侧的列进行排序的,如果最左侧的列值相同,那么按第二列值排序
where 中的 or 前面是索引 后面不是索引
12.InnnDB引擎通过什么技术来保证事务的四大特性的?
持久性 通过 redo log(重做日志)
原子性 通过 undo log(回滚日志)
隔离性 通过 MVCC (多版本并发控制,乐观锁)或 锁机制
一致性 通过 持久性+原子性+隔离性
13.脏读 不可重复度 幻读
脏读:当一个事务 读到了另一个事务 修改后并未提交数据 的事务,叫做脏读
A线程修改数据后并未提交 B线程读取到了A线程的数据,此时A线程发生了回滚,B线程所携带的数据就变成了脏数据
不可重复读: 当一个事务多次读取同一条数据,出现前后数据不一致的情况,叫做不可重复读
A线程读取 1数据,此时B线程修改了1数据,当A线程再次读取是发现在同一个事务内前后读取的数据不相同
幻读:当一个事务多次查询 某个相同条件的 记录行数时,如果两次查询的行数不同,就叫做幻读
14.可重复读可以很大程度上解决幻读问题,但是不能完全解决,为什么?
针对快照读(普通的select语句),通过mvcc的方式解决幻读,当该事务启动后,如果中途有别的事务进行插入操作,那么这个插入的数据是不可见得,因为读取的一直都是事务启动时创建的那个快照
针对当前读,添加next-key lock(将符合条件的行 全锁了,范围行级锁),如果有事务要对该范围内的数据进行插入操作,会被直接阻塞掉,避免了幻读
15.Read View是什么,在MVCC中是如何工作的
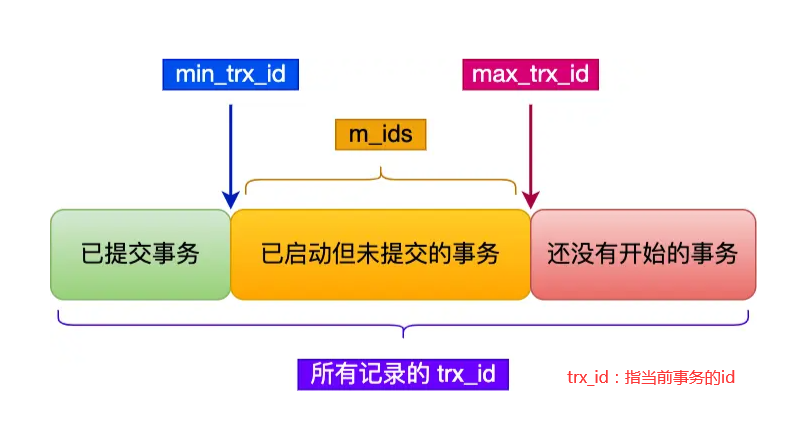
read view 可以理解成是一个快照,它包含了四个属性
m_ids:活跃事务,指启动了但是还没有提交的事务
min_trx_id:id最小事务,指在m_ids中id最小的事务
max_trx_id:创建 read view 时给下一个事务的id
creator_trx_id:创建这个 read view的事务的事务id
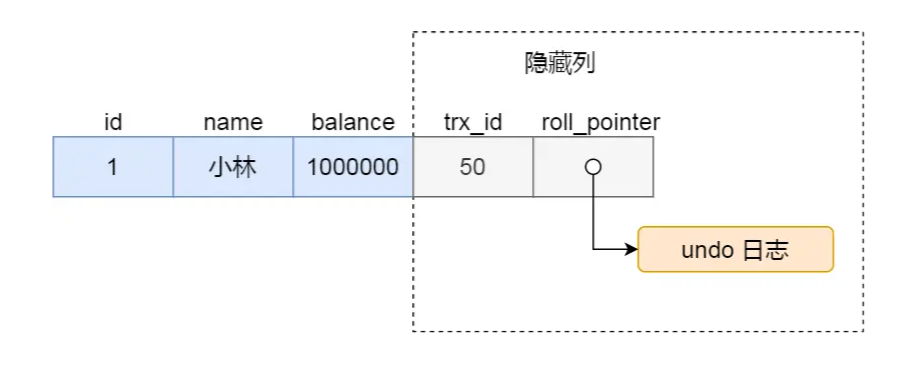
trx_id:当一个事务对当前行做改动之后,会把该事务的事务id存放进该行的 trx_id中
roll_pointer:当每次对该行进行改动之后,都会把旧版本的记录放入 undo log中,发生错误可以直接回滚
一个事务去访问记录时,除了自己更新的记录总是可见的,还有几种情况:
如果记录的trx_id 小于 自身read view 的 min_trx_id 的话,代表着这个事务是在本事务创建 read view 之前就已经提交的事务生成的,所以该版本的记录对当时事务可见
如果记录的trx_id 大于等于 自身的read view 的 max_trx_id 的话,代表着这个事务是在本事务创建 read view 之后才创建的,所以该版本的记录对当前事务不可见
如果记录的trx_id 在m_ids 之间,代表着当前事务依然活跃着 还没有提交,所以这个记录不可见
16.解决Mysql的死锁问题
通过 show engine innodb status 查找死锁信息和错误日志
查找 死锁线程 id
使用 kill 命令 杀死产生死锁的线程

