1.自创模型和以现有模型开始训练区别
1. 训练时间和资源消耗
自己创建一个模型:
优点:如果你有足够的领域知识,并且数据较为简单,自己从头训练模型可能会让你完全掌控训练过程,能够针对特定任务做最优化。
缺点:从头开始训练模型通常需要大量的计算资源和时间,尤其是大规模深度学习模型。训练一个大型模型(如 GPT、BERT)可能需要数周甚至数月的时间,且需要强大的硬件(如多张 GPU)。
使用现有的预训练模型:
优点:可以利用已有的、已经训练好的模型(如 GPT-2/3、BERT 等),并且这些模型通常是用大规模的语料库训练过的,已经具备了很强的语言理解能力。微调这些模型通常需要较少的计算资源和时间。
缺点:你可能无法完全控制模型的结构和优化过程,某些任务上的细节可能无法做到最优化。
2. 数据需求
自己创建一个模型:
优点:你可以完全根据自己的需求来设计模型,收集到的训练数据更贴近你的任务。对于一些非常具体或小众的应用,自己创建模型可以确保模型在这些特定数据上的表现更好。
缺点:自己训练的模型对数据的依赖非常强,可能需要大量的标注数据才能达到好的效果。对于没有大量高质量数据的任务,训练模型可能会出现过拟合或无法收敛的问题。
使用现有的预训练模型:
优点:大部分预训练模型(如 GPT、BERT)已经在大规模的数据集(如 Wikipedia、BookCorpus 等)上进行了训练,因此具备了丰富的语言理解能力。你只需要微调模型,就可以让它适应你具体的任务。
缺点:预训练模型通常是以通用的方式训练的,因此它们可能在某些特定领域的表现不如你期望的好。尽管微调能够改善这个问题,但如果数据集差距过大,效果可能会有限。
3. 模型复杂度
自己创建一个模型:
优点:你可以根据具体任务的需求来设计模型,定制化程度非常高。如果你有很强的领域知识,能够设计出更符合你需求的模型架构,可以充分发挥自己的优势。
缺点:需要更多的调试和验证工作。如果没有经验,可能会设计出过于复杂或不适合当前任务的模型。
使用现有的预训练模型:
优点:大多数现有模型已经过大量的验证和优化,使用它们时基本上可以避免很多不必要的设计错误。你可以直接利用现有的架构和技术,专注于特定任务的微调。
缺点:这些模型的架构和优化已经固定,你无法像自己设计模型那样自由调整。
4. 灵活性和控制
自己创建一个模型:
优点:你可以完全控制模型的结构、训练过程和优化目标,能够对每个细节进行调整,理论上可以实现最优解。对于特定任务或非常复杂的业务场景,自定义模型会有更高的灵活性。
缺点:设计和训练模型的过程非常复杂,需要考虑很多因素,比如数据预处理、超参数调整、避免过拟合等,可能会带来较大的开发难度。
使用现有的预训练模型:
优点:现有的预训练模型通常已经很好地平衡了性能和计算效率,且对于通用任务(如文本分类、生成等)非常适用。通过微调,你可以快速适配到自己的需求。
缺点:对于非常特定或小众的任务,现有模型可能无法完全满足需求,限制了灵活性。比如,如果你的任务涉及非常特殊的语言风格、文化背景或业务需求,现有模型的表现可能不如自己设计的模型。
5. 技术门槛
自己创建一个模型:
优点:如果你有很强的机器学习和深度学习背景,自己设计并训练模型会带来更多的挑战和成就感。你能从底层理解模型的构建过程。
缺点:对于没有丰富深度学习经验的开发者来说,从头开始设计和训练模型的技术门槛较高,可能需要掌握许多知识(如神经网络、梯度下降、损失函数等)。
使用现有的预训练模型:
优点:使用现有模型的技术门槛相对较低。很多开源库(如 Hugging Face Transformers)已经提供了简便的 API 和工具来加载、微调和使用预训练模型。只需要掌握一些基本的深度学习概念和微调技巧,开发就可以进行。
缺点:可能会对一些底层细节无法控制,尽管微调已经很灵活,但如果涉及到模型架构的大幅度改变,仍然需要深入了解深度学习原理。
2.模型B数与显存的关系
1. 参数与显存的基本关系
参数存储:每个参数通常以32位浮点数(FP32)存储,占用 4字节。例如,1B参数的模型仅参数本身需要约 4 GB 显存(1B × 4字节 = 4e9字节 ≈ 4 GB)。
梯度存储:反向传播时为每个参数计算梯度,同样需 4字节(FP32),增加 4 GB。
优化器状态:以Adam优化器为例,需保存动量和方差,各占 4字节,总计 8字节/参数,增加 8 GB。
总计(FP32 + Adam):
每个参数需 16字节(4+4+8),因此显存需求约为:
例如,训练一个7B参数的模型需约 112 GB 显存(7 × 16)。
2. 混合精度训练的影响
使用FP16/BF16混合精度训练可显著降低显存占用:
参数存储:FP16占 2字节,但通常保留FP32主副本(4字节)用于稳定更新。
梯度存储:可能以FP16存储(2字节)或转为FP32(4字节)。
优化器状态:仍以FP32保存动量和方差(8字节)。
总计(混合精度 + Adam):
每个参数约需 12-18字节(如FP16参数+FP32优化器状态),显存需求约为:
例如,7B模型可能需 84-126 GB 显存。
3. 其他影响因素
中间激活值:前向传播的中间结果(如Transformer中的注意力矩阵)占用显存,其大小与批量大小、序列长度相关。对于大模型,激活值可能占显存的30%-50%。
并行策略:数据并行、模型并行或流水线并行会分摊显存,但引入通信开销。
梯度检查点(Gradient Checkpointing):通过牺牲计算时间换取显存,可减少激活值占用约60%-70%。
4. 实际估算示例
GPT-3 175B:
若以FP32 + Adam训练,理论显存需求为 175×16=2800175×16=2800 GB。实际中通过混合精度、模型并行和梯度检查点等技术,可在数千GB显存的多卡集群上训练。Llama 2 7B:
混合精度下约需 84-112 GB 显存,通常需多张A100(40/80GB)显卡。
总结
显存需求与参数量呈线性关系,比例系数由数据类型(FP32/FP16)和优化器决定。
简化公式:
FP32 + Adam:每参数 16字节
混合精度 + Adam:每参数 12-18字节
实际训练时需额外考虑激活值、并行策略和显存优化技术。
3.使用现有模型进行训练
1. 选择框架
TensorFlow 或 PyTorch:这两个是最常用的深度学习框架。对于自然语言处理(NLP)任务,推荐使用 Hugging Face's Transformers 库,它是建立在这些框架之上的,提供了许多预训练模型,适用于文本生成和对话系统。
Hugging Face Transformers:这是目前最流行的 NLP 库之一,支持大量预训练模型,特别适合生成文本和对话。你可以使用
GPT-2或GPT-3等模型进行微调。
2. 准备训练数据
数据收集:你需要收集大量符合草神风格的文本,最好是角色的对话内容。
文本处理:需要对数据进行清理、分词、去除噪声等操作。可以使用
nltk或spaCy库来处理文本数据。
3.下载模型:https://huggingface.co/
4.
4.算法
1. 数据预处理阶段
算法/技术
TF-IDF / 关键词提取
作用:从原始文本中提取纳西妲相关的关键词(如“世界树”、“梦境”、“智慧”),辅助筛选和标注数据。
原理:
通过计算词语的权重(重要性),公式为: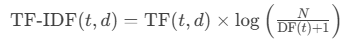
TF(词频):词语在单篇文档中的出现频率。
IDF(逆文档频率):衡量词语在所有文档中的稀有程度(例如“世界树”在《原神》文本中是关键稀有词)。
应用:
筛选出纳西妲相关的关键词(如“智慧”、“梦境”),用于数据标注或过滤无关文本。
BERT/Spacy 的 NER(命名实体识别)
作用:自动识别文本中与《原神》世界观相关的实体(如“草神”、“须弥”、“兰那罗”),用于知识标签标注。
原理:
基于预训练的BERT模型,对文本中的实体进行分类(如人物、地点、元素)。输入:句子 → BERT编码 → 全连接层 → 实体标签(如
B-草神,I-地点)。
应用:
自动识别《原神》世界观中的关键实体(如“须弥城”、“兰那罗”),为后续对话生成提供上下文知识。
文本相似度聚类(如 K-Means + Sentence-BERT)
作用:将纳西妲的台词按语义相似度分组,发现高频主题(如“引导他人”、“哲理思考”),优化数据分布。
原理:
Sentence-BERT:将句子映射为语义向量(通过Siamese网络结构)。
K-Means:将句子向量聚类,发现相似主题(如“哲学思考” vs “战斗指导”)。
应用:
确保训练数据覆盖纳西妲的多样对话风格,避免模型偏向单一主题。
2. 模型训练阶段
核心算法
Transformer 架构(如 GPT、Llama)
作用:作为生成模型的基础结构,通过自注意力机制捕捉长距离上下文,生成连贯的文本。
核心机制:
自注意力(Self-Attention):
计算每个词与其他词的关联权重,公式: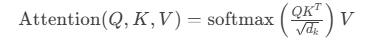
允许模型捕捉长距离依赖(例如“世界树”与“草元素”的关联)。
位置编码(Positional Encoding):
为输入序列添加位置信息,避免RNN的顺序计算瓶颈。
应用:
GPT、Llama 等生成模型的基础架构,负责生成连贯的文本。
监督微调(Supervised Fine-Tuning, SFT)
作用:用清洗后的对话数据(用户输入→纳西妲风格回复)调整预训练模型,使其学习角色的语言风格和知识。
流程:
输入格式:将对话数据构造为
[用户输入] → [纳西妲回复]的序列。训练目标:最大化纳西妲回复的似然概率,损失函数为交叉熵:
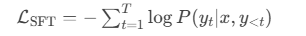
关键细节:
在输入前添加角色描述(如“你是纳西妲,草之神,用温柔智慧的语气回答”),强化角色认知。
使用梯度裁剪(Gradient Clipping)防止梯度爆炸。
强化学习(RLHF, PPO)
作用:通过人类反馈优化生成结果,例如:
定义奖励函数,惩罚不符合角色性格的回复(如“攻击性语气”)。
使用近端策略优化(PPO)更新模型参数。
流程:
奖励建模(Reward Model):
训练一个分类器,判断生成文本是否符合纳西妲风格(如“温柔程度”评分)。
近端策略优化(PPO):
通过策略梯度更新模型参数,最大化奖励函数的期望值:
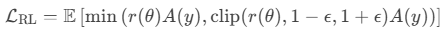
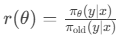 为策略比率,A(y)是优势函数。
为策略比率,A(y)是优势函数。
应用:
精细调整生成风格(例如减少过于口语化的回答)。
低秩适配(LoRA)
作用:高效微调大模型,冻结原始参数,仅训练低秩分解矩阵,显著减少显存占用。
原理:
冻结原始模型权重,仅训练低秩分解矩阵
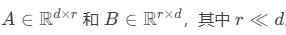
更新公式:
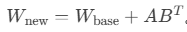
优势:
参数效率:训练参数量减少 90% 以上(例如 7B 模型仅需训练 0.1B 参数)。
避免灾难性遗忘(原始知识保留在冻结权重中)。
检索增强生成(RAG)
作用:当模型需要回答复杂世界观问题时,从《原神》知识库中检索相关内容,辅助生成准确回答。
流程:
构建知识库:将《原神》官方文档转换为向量(使用 BERT 或 BGE 模型)。
检索-生成:
对用户输入 x,检索最相关的文档片段 z。
将 x 和 z 拼接后输入生成模型:P(y∣x,z)。
应用:
确保模型回答符合世界观设定(例如“世界树的结构”)。
3. 生成控制技术
解码策略
温度调节(Temperature Scaling)
作用:控制生成多样性(低温→保守,高温→创意),适配纳西妲“温和但富有哲理”的风格。
公式:

Top-p(Nucleus Sampling)
作用:仅从概率累积超过阈值 p 的候选词中采样,避免生成不合理内容。
原理:
仅从累积概率超过阈值 p 的最小候选词集合中采样。例如 p=0.9,选择概率最高的词直到总和 ≥ 0.9。
优势:
避免低概率词干扰生成质量(如俚语或冲突内容)。
重复惩罚(Repetition Penalty)
作用:抑制重复短语(如反复出现“世界树”),提升回答多样性。
实现:
对已生成的 token 降低其后续概率:
4. 评估阶段
算法/技术
困惑度(Perplexity)
作用:衡量生成文本的流畅度(值越低越好)。
公式:
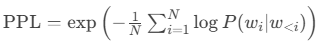
值越低,模型对测试数据的预测越自信(衡量流畅度)。
BLEU/ROUGE
作用:对比生成文本与真实台词的相似度(侧重表面词匹配)。
BERTScore
作用:通过语义嵌入计算生成文本与参考文本的相似度(侧重语义匹配)。
原理:
用 BERT 模型分别编码生成文本和参考文本。
计算 Token 间的余弦相似度加权召回率(Recall)、精确率(Precision)。
优势:
比 BLEU 更注重语义匹配(例如接受同义词替换)。
风格分类器(Fine-tuned BERT)
作用:训练一个二分类模型,判断生成文本是否符合“纳西妲风格”(如温柔、哲理性)。
训练方法:
收集正样本(纳西妲台词)和负样本(其他角色或随机文本)。
微调 BERT 模型进行二分类(输出“是否符合风格”)。
应用:
自动判断生成文本的温柔程度、哲理性等。
5. 部署优化
模型量化(Quantization)
作用:将模型权重从 FP32 转换为 INT8/INT4,减少推理时的显存占用和延迟。
知识蒸馏(Knowledge Distillation)
作用:将大模型(如 70B)压缩为小模型(如 7B),保留核心能力,便于部署。
各阶段算法协作流程图
数据收集 → TF-IDF/聚类 → 清洗标注
↓
预训练模型 → SFT微调 → RLHF优化 → LoRA适配
↓
RAG检索 → 生成(温度调节/Top-p) → 评估(困惑度/BERTScore) 基础生成:Transformer + SFT(核心语言风格学习)
风格强化:RLHF + 风格分类器(精准控制性格)
高效训练:LoRA(节省资源)+ 量化(加速推理)
知识保障:RAG(避免虚构世界观)+ NER(自动标注)
数据层:TF-IDF 和 NER 提取关键信息 → 构建高质量对话数据集。
训练层:
SFT 学习基础语言风格 → RLHF 精细化调整 → LoRA 降低计算成本。
RAG 补充外部知识(避免“一本正经地胡说八道”)。
生成层:温度调节 + Top-p 控制多样性和安全性。
评估层:困惑度 + BERTScore + 风格分类器三重验证。

